TL;DR
- Muon is the de facto matrix aware optimizer for LLM pretraining, which is basically next token classification on text via supervised learning. Muon orthogonalizes the momentum matrix through a few Newton Schulz (NS) iterations, pushing every singular value of the momentum to one.
- When we move beyond LLM pretraining along three axes (a different modality, a different loss, or a different learning paradigm), Muon’s uniform spectral whitening turns out to be the wrong inductive bias.
- We propose Pion (sPectral hIgh pass Optimization on momeNtum), a drop in replacement for Muon’s NS iteration. It changes only the polynomial coefficients used inside NS, keeps the same per step cost, and realizes a sharp spectral high pass that anchors the informative leading singular values at one while suppressing the noisy tail toward zero.
Where Muon Lives Today: LLM Pretraining
For a weight matrix \(\boldsymbol{\Theta} \in \mathbb{R}^{m \times n}\), given a stochastic gradient \(\mathbf{G}_t\) and a momentum buffer \(\mathbf{M}_t = \mu \mathbf{M}_{t-1} + \mathbf{G}_t\), Muon performs the steepest descent step under the spectral norm:
\[\boldsymbol{\Theta}_t = \boldsymbol{\Theta}_{t-1} - \eta \, \mathrm{msign}(\mathbf{M}_t).\]If \(\mathbf{M} = \mathbf{U} \boldsymbol{\Sigma} \mathbf{V}^\top\) is the compact SVD, then
\[\mathrm{msign}(\mathbf{M}) = \mathbf{U}\, \mathrm{sign}(\boldsymbol{\Sigma})\, \mathbf{V}^\top = \mathbf{U} \mathbf{V}^\top.\]Every nonzero singular value is mapped to one. This is what we call uniform spectral whitening.
Computing an SVD per step is too expensive at scale, so Muon approximates \(\mathrm{msign}\) by a small number of Newton Schulz (NS) iterations. After normalizing the input as \(\mathbf{X} \leftarrow \mathbf{X} / (\|\mathbf{X}\|_F + \epsilon)\), each NS step applies an odd quintic matrix polynomial,
\[\mathbf{X} \leftarrow a\, \mathbf{X} + b\, \mathbf{X}\mathbf{X}^\top \mathbf{X} + c\, \mathbf{X}(\mathbf{X}^\top \mathbf{X})^2,\]with the canonical coefficients \((a, b, c) = (3.4445,\ -4.7750,\ 2.0315)\). By the identity \(\mathbf{X}(\mathbf{X}^\top \mathbf{X})^j = \mathbf{U}\, \boldsymbol{\Sigma}^{2j+1}\, \mathbf{V}^\top\), an NS step preserves the singular vectors and reshapes each singular value through a scalar polynomial on \([0, 1]\):
\[f(\sigma;\, a, b, c) \,\triangleq\, a\sigma + b\sigma^3 + c\sigma^5.\]So designing an NS iteration reduces to designing \(f\) on \([0, 1]\). Muon’s NS is constructed so that repeated application drives every \(\sigma \in (0, 1]\) toward one (panel a below).
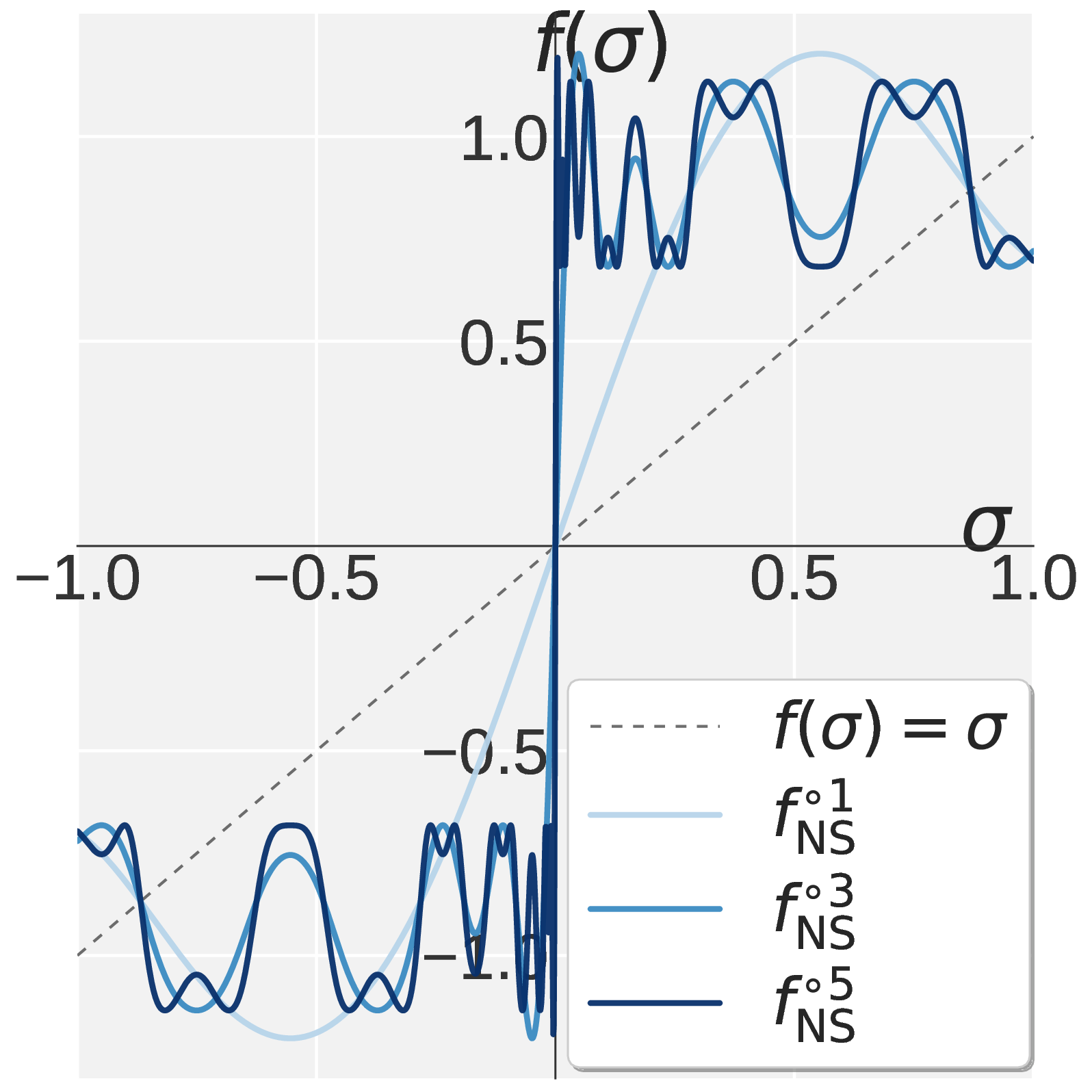
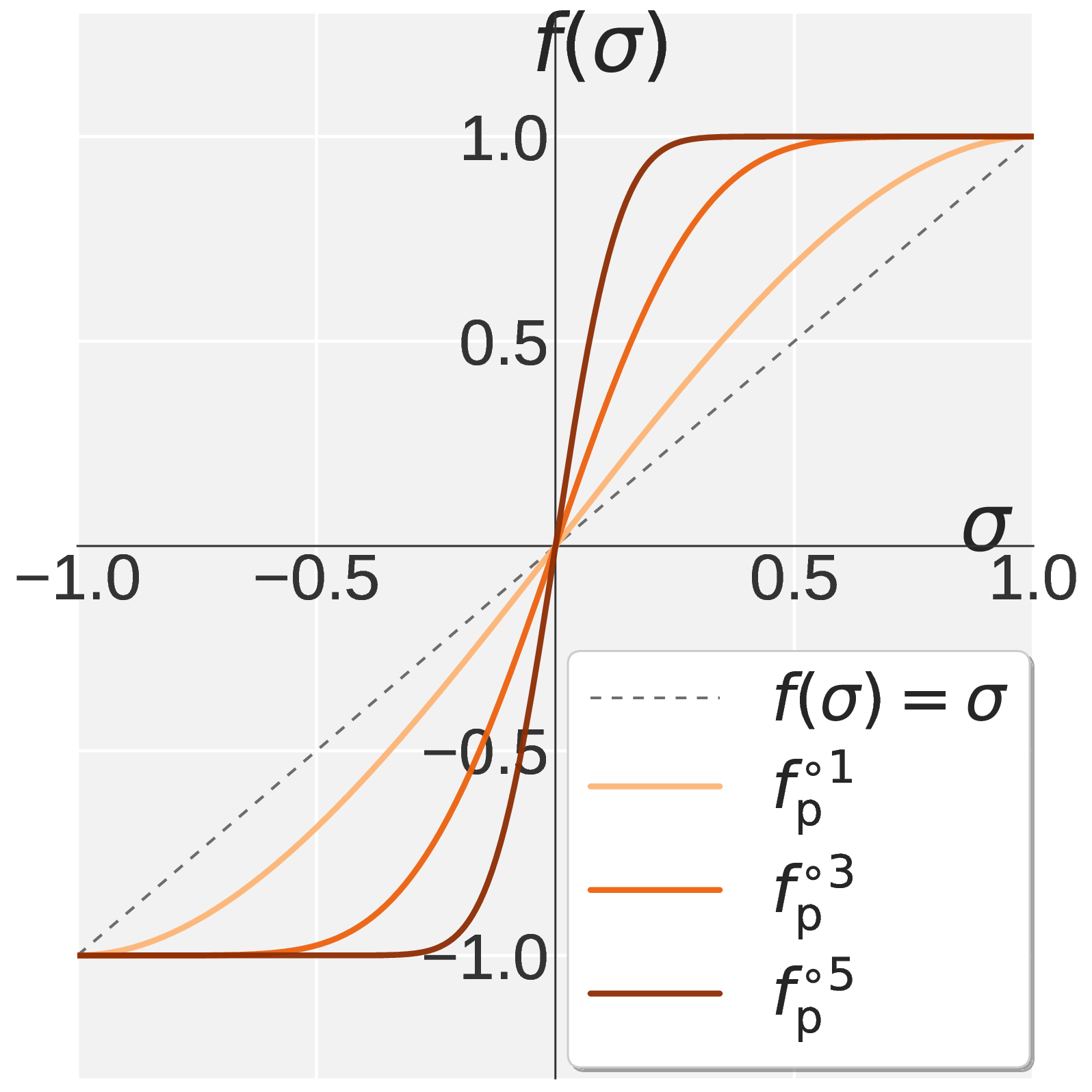
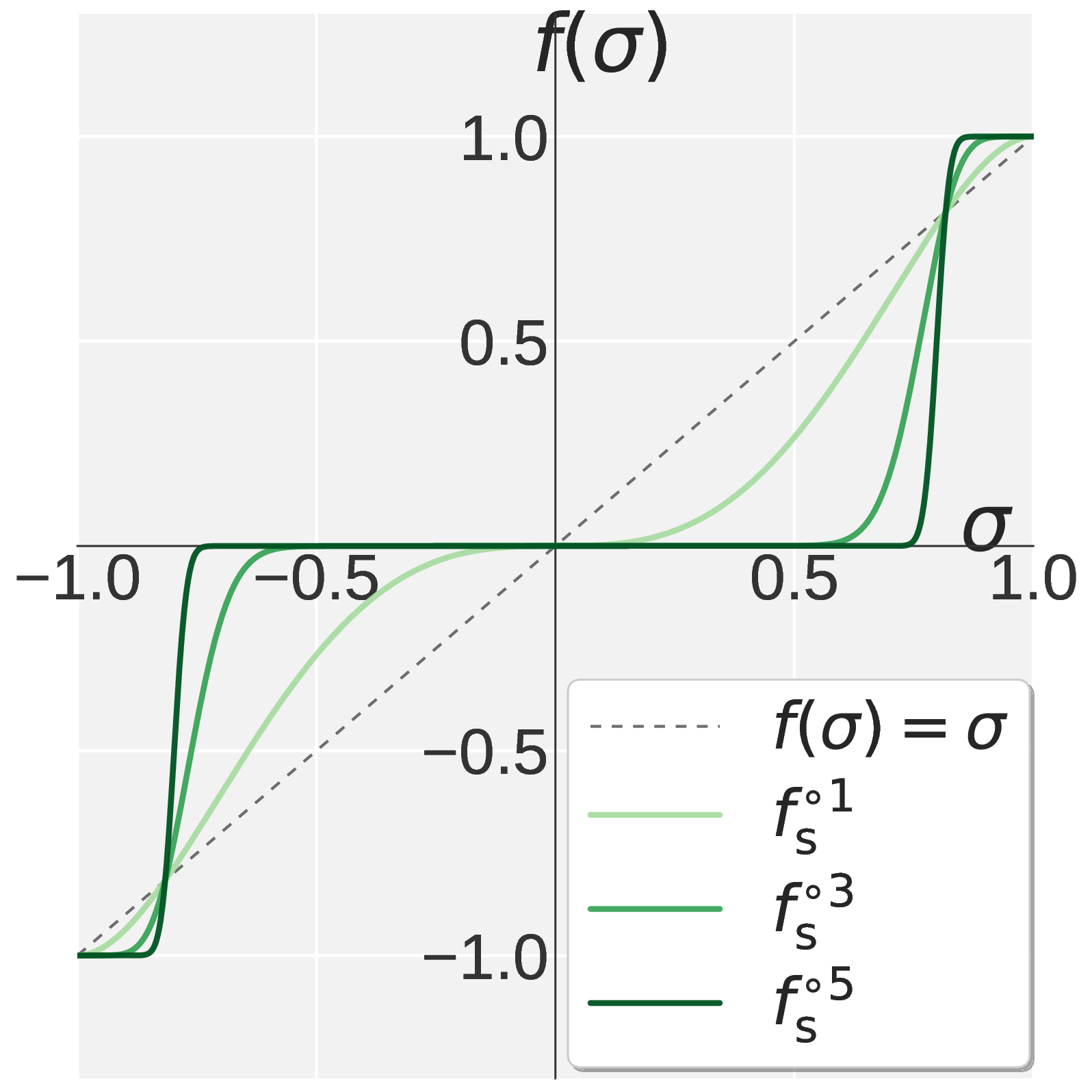
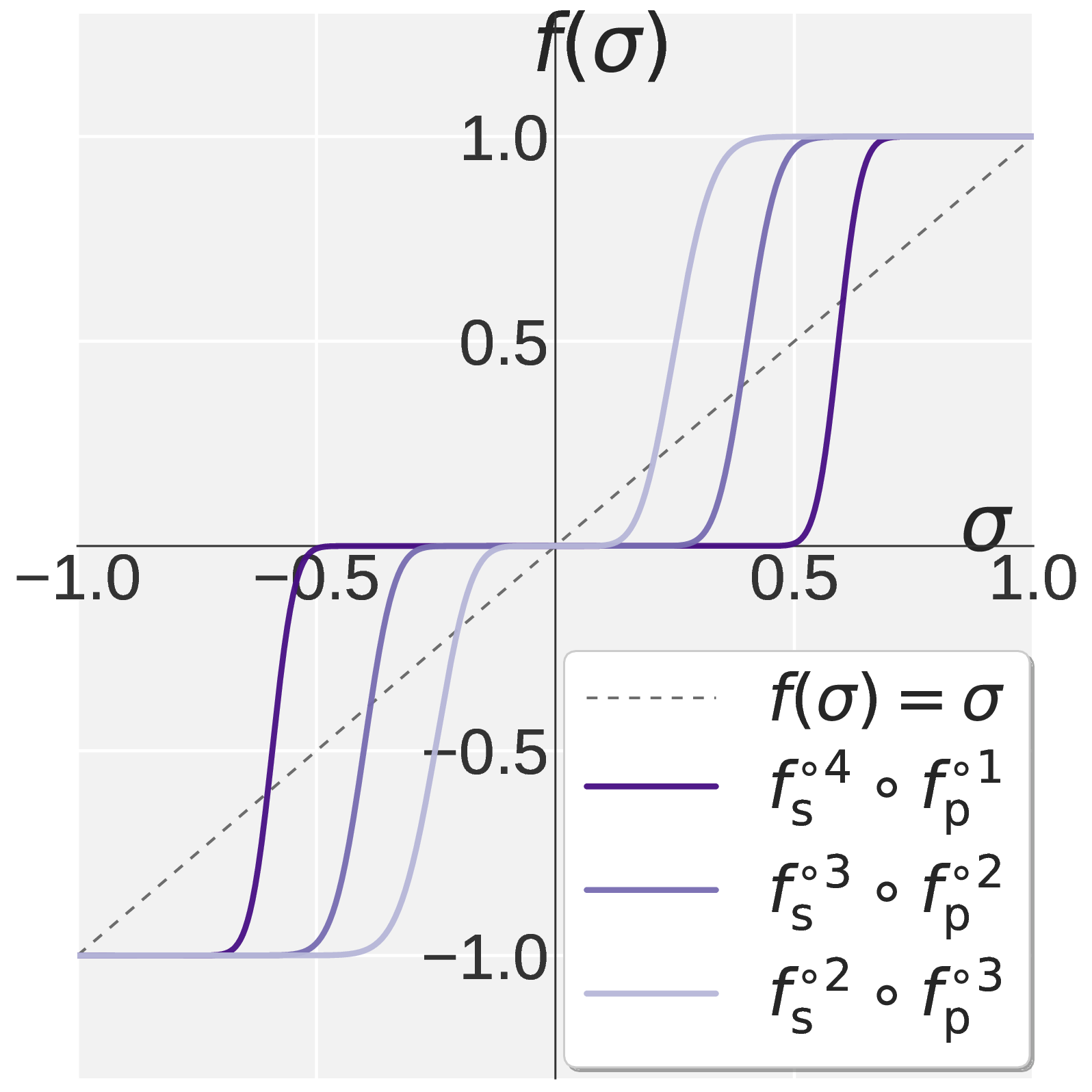
Figure 1. Visualization of $$f(\sigma)$$ on $$\sigma \in [0, 1]$$. Muon (a) drives every singular value toward one. Pion combines Promotion (b) with Suppression (c) to obtain the high pass profile in (d).
LLM pretraining is a classification task (predict the next token over the vocabulary), uses text as the only modality, and is performed under supervised learning. With clean dense supervision and full rank text gradients, Muon’s uniform whitening is a sensible inductive bias: it spreads optimization signal uniformly across all spectral directions, and consistently improves over AdamW.
Three Axes of Generalization Beyond LLM Pretraining
LLM pretraining occupies one specific corner of the design space. Three orthogonal axes can move us out of that corner.
| Axis | LLM pretraining | Generalization direction | Representative testbed |
|---|---|---|---|
| Modality | text | vision, robot action | VLA training (vision language action) |
| Loss | classification (next token) | regression, generative (flow matching) | VLA action heads (\(\ell_1\) regression and flow matching) |
| Paradigm | supervised learning | reinforcement learning | RLVR post training (GRPO, GMPO) |
VLA training naturally combines axes 1 and 2: it adds the action modality and replaces classification with regression or generative losses. RLVR isolates axis 3: it keeps the LLM and its tokenizer but switches from supervised next token loss to policy gradient on a verifiable reward.
The rest of the page asks the same question along each axis: does Muon’s uniform spectral whitening still help, or does it become the wrong inductive bias?
Axes 1 and 2: A Different Modality and a Different Loss (VLA)
A VLA model is factorized into a vision encoder, a language backbone, and an action head. The vision and language modules still consume text and image tokens, but the action head is a new modality (it consumes joint actions of robots). The action head also uses non classification losses: either an \(\ell_1\) regression head (e.g., VLA Adapter) or a flow matching generative head (e.g., VLANeXt). These two design choices, the action modality and the regression style loss, are tightly coupled by construction.
We measure the spectral structure of each module’s gradient via the effective rank (erank) of \(\mathbf{G} \in \mathbb{R}^{m \times n}\):
\[\mathrm{erank}(\mathbf{G}) \,\triangleq\, \exp\!\Big( H(\mathbf{p}) \Big), \quad H(\mathbf{p}) = -\sum_{i=1}^n p_i \log p_i, \quad p_i = \frac{\sigma_i(\mathbf{G})}{\sum_j \sigma_j(\mathbf{G})}.\]A higher erank means gradient energy is spread across many singular directions; a lower erank means it concentrates in a few dominant ones.
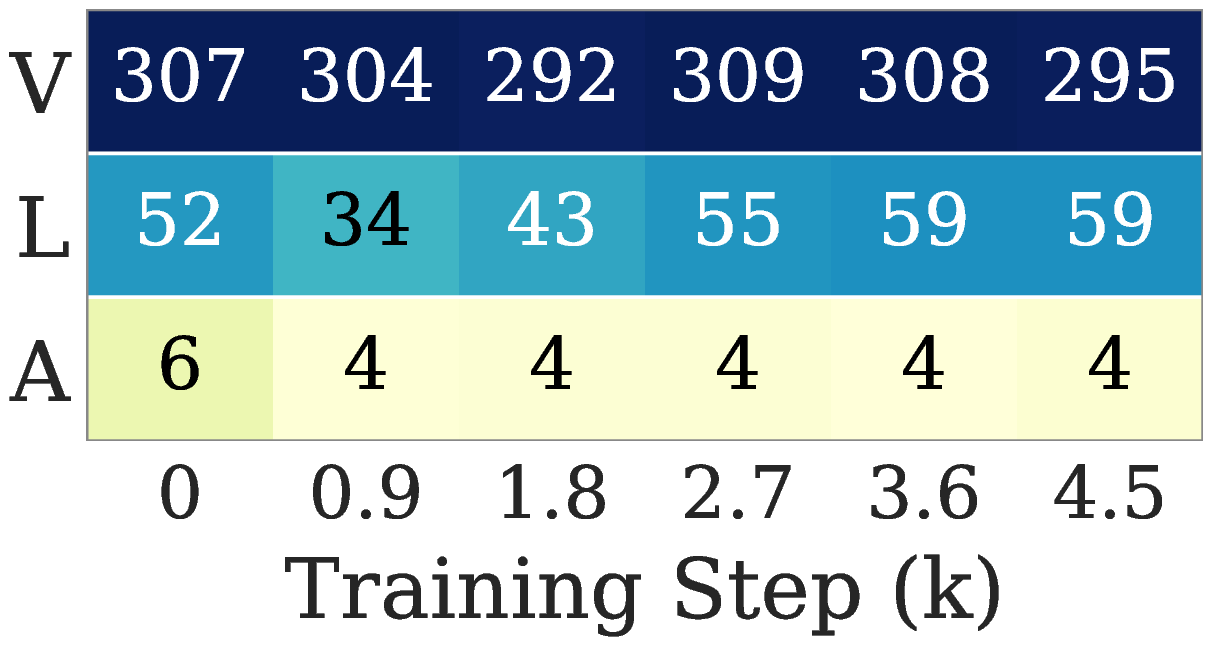
The ordering is stable across training: vision is highest, language is intermediate, the action gradient is consistently the lowest. Both the modality switch (rich pixels and tokens become a tiny continuous action vector) and the loss switch (one hot classification becomes regression or generative matching) push the action gradient toward low effective rank.
When Muon is applied uniformly to such a low erank gradient, it lifts the noisy tail directions to the same magnitude as the few informative leading directions. The resulting update is dominated by spectral floor noise.
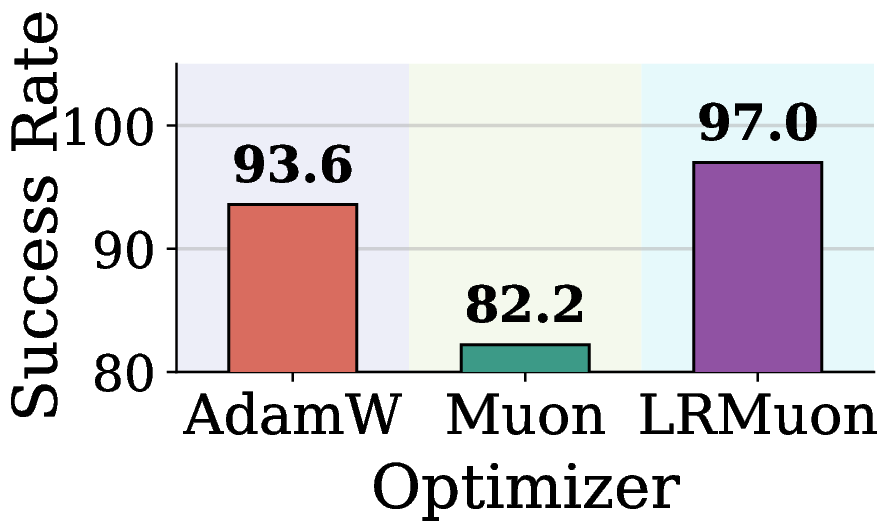
A natural workaround is Low Rank Muon (LRMuon), which projects the momentum onto a top \(k\) subspace via SVD or Gaussian sketching before NS. LRMuon does close the accuracy gap, but the explicit projection inflates wall clock by about an order of magnitude, and forces a fixed rank \(k\) that cannot adapt across layers and training steps.
Limitation 1 (modality + loss). Conventional Muon is not adaptive to the rank heterogeneity introduced by new modalities and non classification losses. Explicit low rank projection helps but breaks scalability.
Axis 3: A Different Learning Paradigm (RLVR)
RLVR keeps the LLM and the text modality; it changes the learning paradigm. Instead of a token level supervised loss, the policy is updated by policy gradient against a rule based, verifiable reward. We use GRPO (group relative policy optimization) and GMPO as representative algorithms.
To compare paradigms, we measure the per step gradient signal to noise ratio of a layer’s weight matrix:
\[\mathrm{SNR}(\mathbf{G}) \,\triangleq\, \frac{\|\mathbb{E}[\mathbf{G}]\|_F^2}{\mathbb{E}\big[\,\|\mathbf{G} - \mathbb{E}[\mathbf{G}]\|_F^2\,\big]}.\]A higher SNR means a cleaner gradient signal.
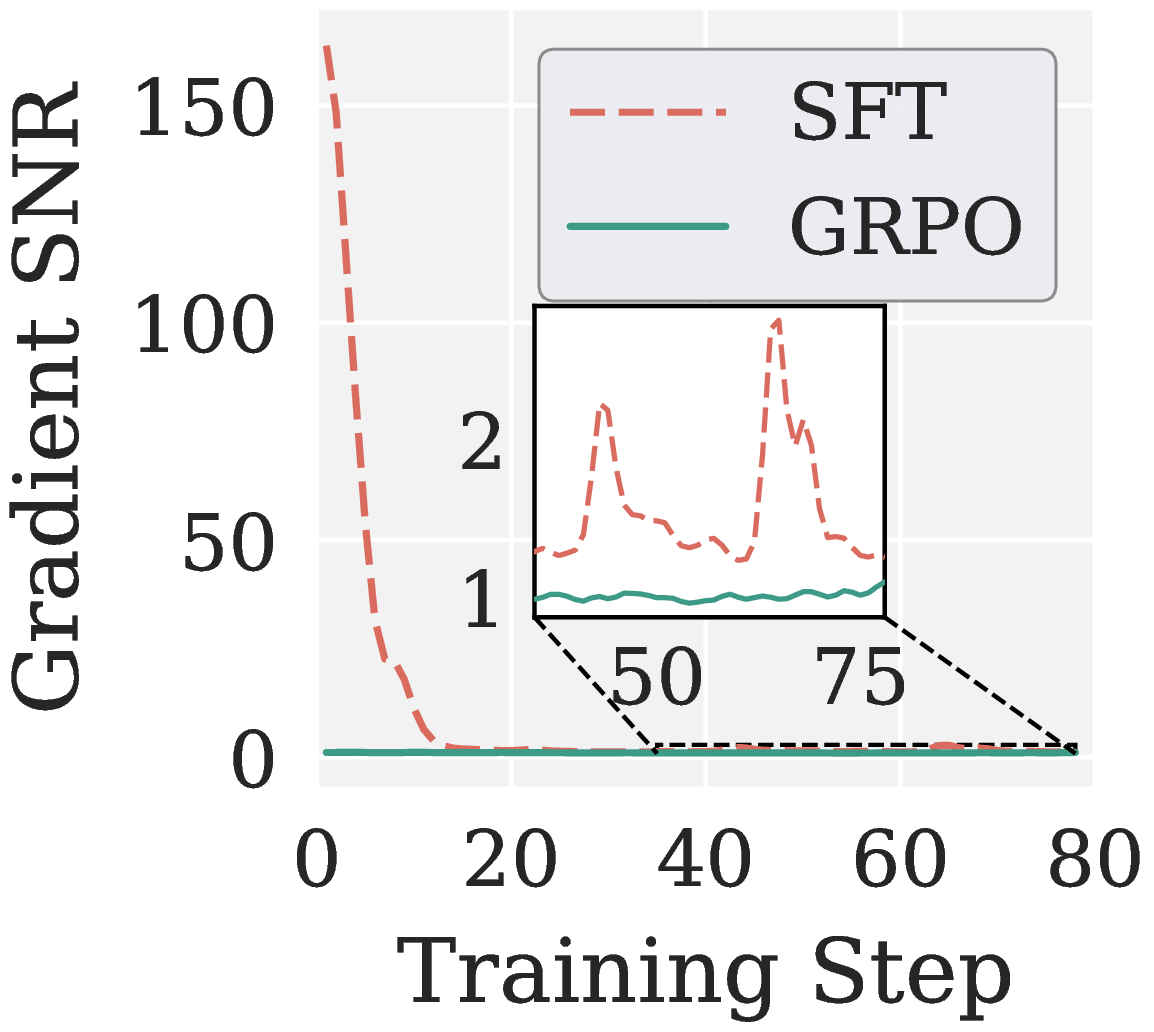
GRPO has much lower SNR than SFT throughout training. Two structural reasons:
- Coarser supervision granularity. SFT receives token level teacher signals, GRPO uses trajectory level rewards, so each token gets a much sparser learning signal.
- Stabilization mechanisms. Importance sampling, clipping, and group relative normalization reweight or zero out parts of the per token gradients, which inflates variance.
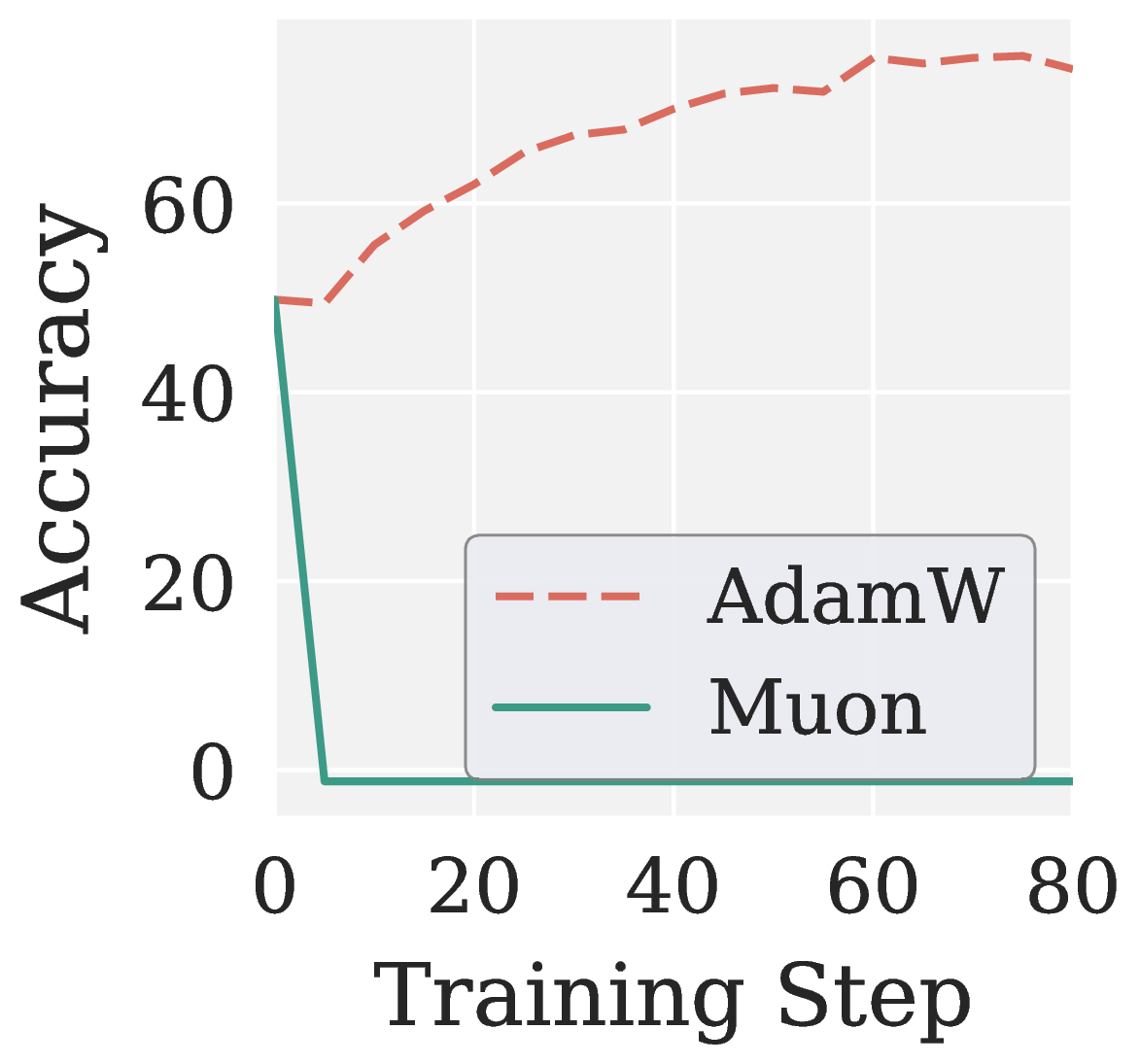
When Muon is run on top of these low SNR gradients, the uniform whitening lifts the variance of the noisy directions to the same magnitude as the informative ones. The policy collapses within a few steps.
A second issue specific to the RLVR paradigm is that Muon’s NS treats each weight matrix as a single block. Attention projections inherit per head specialization from pretraining, so different heads have different Frobenius norms and want updates at different scales. Muon ignores this structure and applies one orthogonalization to the whole projection.
Limitation 2 (paradigm). Muon’s uniform spectral whitening amplifies noisy directions in low SNR RLVR gradients, making it ill suited for noise sensitive post training. It also discards the per head structure inherited from pretraining.
A Unified Spectral Diagnosis
Although Limitations 1 and 2 originate from different sources (low effective rank along the modality and loss axes, low SNR along the paradigm axis), they share one spectral signature. In the SVD of \(\mathbf{M}_t\), the few leading singular values carry the informative descent direction, while the long tail of small singular values is dominated by noise: a spectral floor when erank is low, stochastic estimation noise when SNR is low. Muon’s \(\mathrm{msign}\) lifts the tail to the magnitude of the head and corrupts the update in both regimes.
The natural remedy is a spectral high pass: anchor the informative head near one, contract the noisy tail toward zero. This is exactly what Pion realizes.
Pion: A High Pass Newton Schulz Iteration
Since each NS step reshapes \(\sigma \in [0, 1]\) through the scalar polynomial \(f(\sigma; a, b, c) = a\sigma + b\sigma^3 + c\sigma^5\), designing an NS iteration reduces to designing \(f\). A single such polynomial cannot produce a sharp high pass on the unit interval, so Pion splits the default \(k = 5\) NS steps into two stages with different coefficients:
- a Promotion polynomial \(f_{\mathrm{p}}\) applied for \(k_{\mathrm{p}}\) steps, which lifts dominant singular values toward one while preserving their relative order;
- a Suppression polynomial \(f_{\mathrm{s}}\) applied for \(k_{\mathrm{s}} = k - k_{\mathrm{p}}\) steps, which pins large singular values near one and contracts smaller ones toward zero.
The cutoff is controlled by the single hyperparameter \(k_{\mathrm{p}} \in \{0, 1, \ldots, 5\}\).
The Promotion Stage
We require three constraints on \(f_{\mathrm{p}}\):
- (P1) Fixed point. \(f_{\mathrm{p}}(1) = 1\), so any direction already at one stays there.
- (P2) First order stationarity. \(f_{\mathrm{p}}'(1) = 0\), so the anchor at one is flat.
- (P3) Boundary concavity. \(f_{\mathrm{p}}''(1) \leq 0\) together with (P2) ensures \(\sigma = 1\) is a maximum so the iteration does not curve upward past one near the boundary.
Solving (P1)(P2) leaves a one parameter family. Combining (P3) with monotonicity on \([0, 1]\) carves out the feasible interval \(a_{\mathrm{p}} \in [0, 1.875]\). Since \(f_{\mathrm{p}}'(0) = a_{\mathrm{p}}\) controls how strongly each step lifts small singular values, we pick the largest feasible slope:
\[f_{\mathrm{p}}(\sigma) = 1.875\, \sigma \,-\, 1.25\, \sigma^3 \,+\, 0.375\, \sigma^5.\]A pleasant byproduct is that the derivative becomes a perfect square,
\[f_{\mathrm{p}}'(\sigma) = 1.875\, (1 - \sigma^2)^2 \,\geq\, 0,\]so monotonicity on \([0, 1]\) holds automatically.
The Suppression Stage
The suppression polynomial inherits \(f_{\mathrm{s}}(1) = 1\) and \(f_{\mathrm{s}}'(1) = 0\), and adds a spectral filtering condition \(f_{\mathrm{s}}'(0) = 0\). Removing the linear term near the origin forces small singular values to be driven to zero by the higher order terms. The unique solution is
\[f_{\mathrm{s}}(\sigma) = 2.5\, \sigma^3 \,-\, 1.5\, \sigma^5.\]Putting It Together
Chaining \(k_{\mathrm{p}}\) Promotion steps with \(k_{\mathrm{s}}\) Suppression steps gives Pion’s high pass NS iteration. Fixing \(k = 5\) preserves Muon’s per step cost. Panel (d) of Figure 1 shows the resulting profile: a sharp transition between a pinned region near one and a filtered region near zero, with \(k_{\mathrm{p}}\) controlling the cutoff. Empirically, suppression dominant allocations with \(k_{\mathrm{s}} \geq 3\) work best for both VLA and RLVR.
Takeaway. Pion is a drop in replacement for Muon’s NS iteration. It uses the same control flow, the same per step cost, and changes only the polynomial coefficients.
Per Head Mode for RLVR
Pion has two application modes:
- Default mode applies the iteration to each weight matrix as a single block (mirrors Muon).
- Per head mode first reshapes each attention projection along its head dimension into multiple per head sub matrices, then runs the iteration independently on each.
Since the inner products \(\mathbf{X}^\top \mathbf{X}\) are already batched along the head dimension after the reshape, the per head mode is free over the default mode.
We use the default mode for VLA (the action head is trained from scratch and has no head structure to preserve) and the per head mode for RLVR. RLVR starts from a pretrained LLM whose attention layers have heterogeneous per head Frobenius norms, and these per head norms govern attention sharpness and gradient magnitudes. Default mode Pion gives an essentially flat update variance across heads, while the per head mode preserves the heterogeneous, layer dependent updates required to keep that pretrained structure.
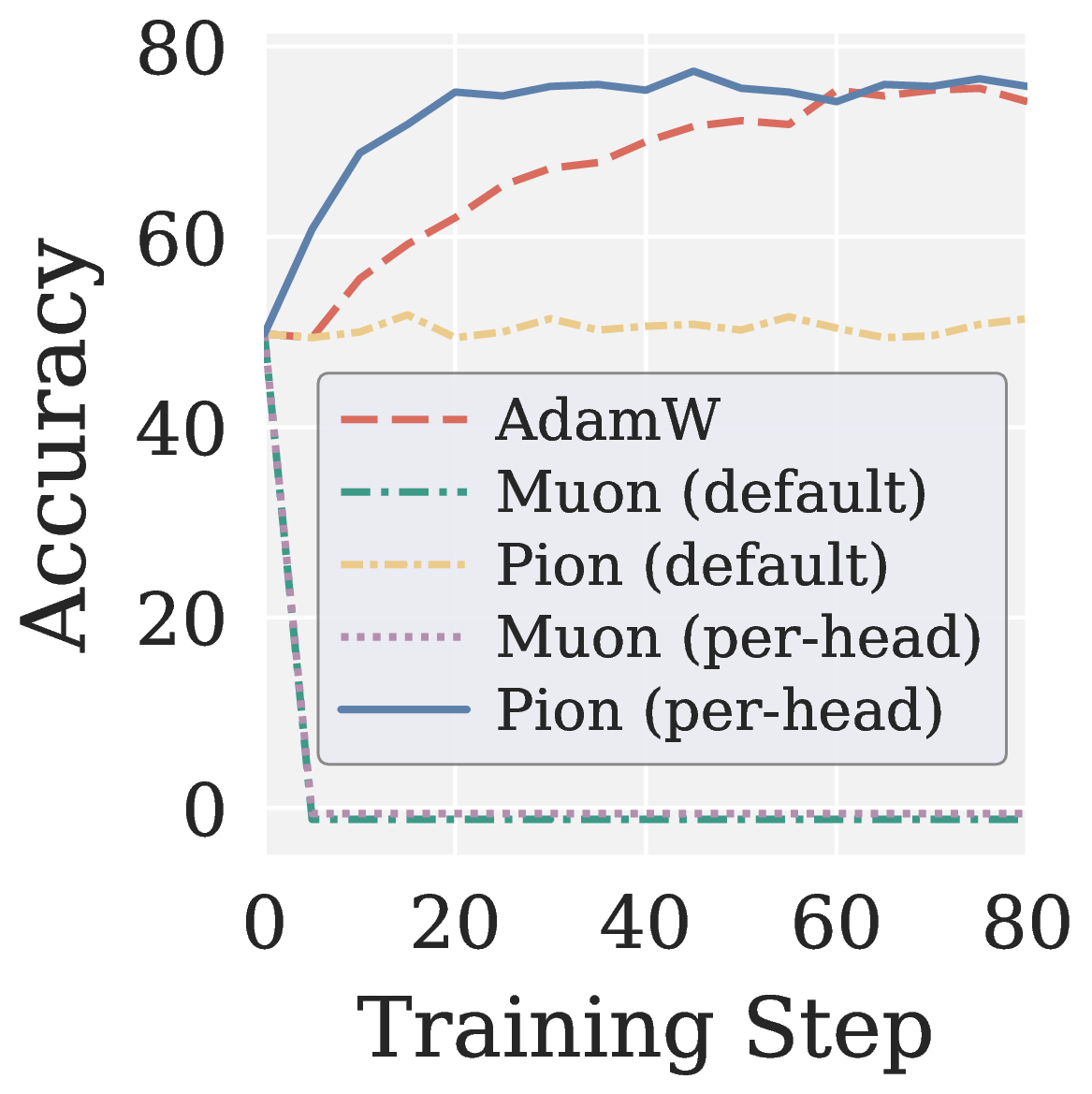
This isolates two complementary findings:
- The spectral high pass is the primary driver of RLVR stability. Per head Muon (the same reshape on top of Muon’s NS) still collapses.
- The per head reshape is an auxiliary mechanism that preserves head heterogeneity inherited from pretraining, and it pushes per head Pion past AdamW.
Experiments
Pion is evaluated on two testbeds that span all three axes:
- VLA training (axes 1 and 2) with two architectures: \(\ell_1\) regression based VLA Adapter and flow matching based VLANeXt, on LIBERO and LIBERO Plus.
- RLVR post training (axis 3) with GRPO and GMPO on Qwen3 1.7B and Qwen3 4B over MATH and GSM8K.
Three optimizer configurations are compared in each setting: AdamW, Muon, and Pion.
VLA: Pion Outperforms Muon Across Both Heads
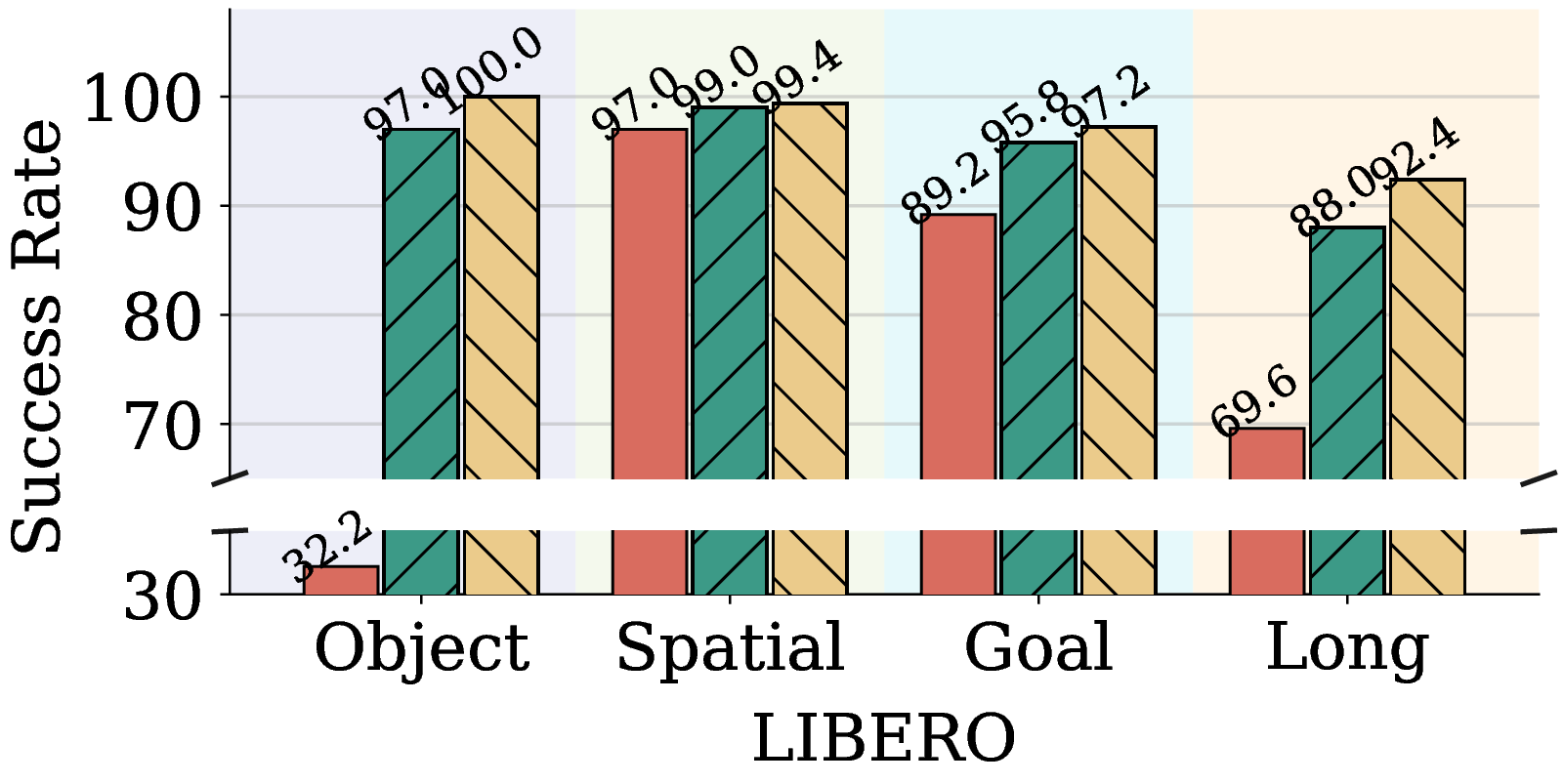
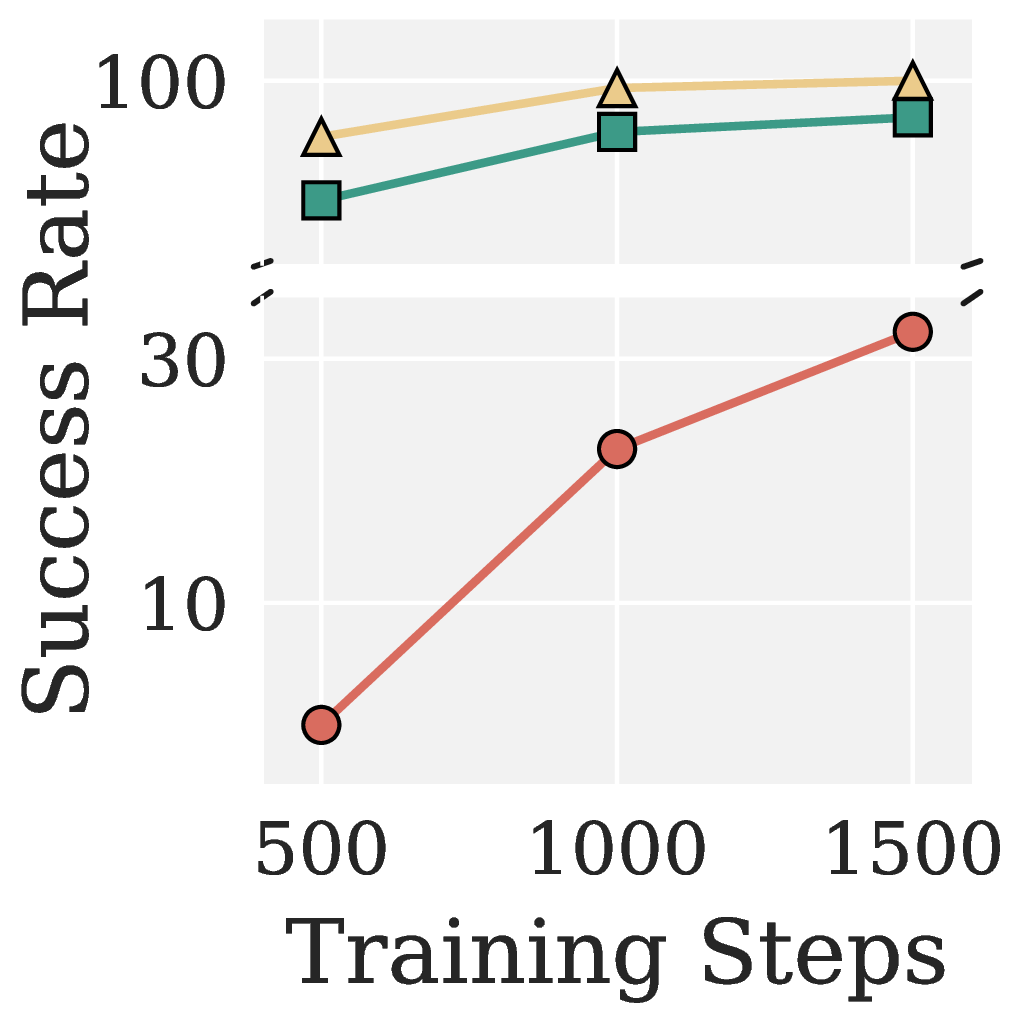
Figure 7. AdamW, Muon, and Pion for VLA Adapter on LIBERO.
On VLA Adapter / LIBERO Object, Pion reaches 95.4% success at 500 steps and saturates at 100% by 1500 steps. AdamW needs many more steps and Muon stays consistently behind. Pion outperforms Muon on every one of the four LIBERO suites.
For VLANeXt (flow matching), Pion not only wins on the clean LIBERO benchmark but also amplifies its advantage on the harder LIBERO Plus split, especially under language (\(+9\) pts), noise (\(+6\) pts), and robot (\(+6\) pts) perturbations. This suggests that the high pass mechanism produces more robust policies under distribution shift, consistent with the picture that uniform whitening overamplifies non generalizable noise directions.
| Optimizer | LIBERO | LIBERO Plus | Background | Camera | Language | Layout | Light | Noise | Robot |
|---|---|---|---|---|---|---|---|---|---|
| AdamW | 79.45 | 64.57 | 68.97 | 70.38 | 54.50 | 61.80 | 76.35 | 66.37 | 47.04 |
| Muon | 93.65 | 72.34 | 82.72 | 68.00 | 77.53 | 76.21 | 86.17 | 69.98 | 57.36 |
| Pion (Ours) | 96.35 | 75.93 | 84.53 | 70.88 | 86.93 | 76.71 | 90.67 | 76.09 | 63.18 |
Table 1. AdamW, Muon, and Pion for VLANeXt on LIBERO and LIBERO Plus. Best in bold.
RLVR: Pion Succeeds While Muon Collapses
Across eight RLVR settings (GRPO and GMPO times Qwen3 1.7B and Qwen3 4B times MATH and GSM8K), Muon consistently collapses to near zero accuracy. Pion not only recovers a meaningful training signal but also outperforms AdamW with faster convergence.
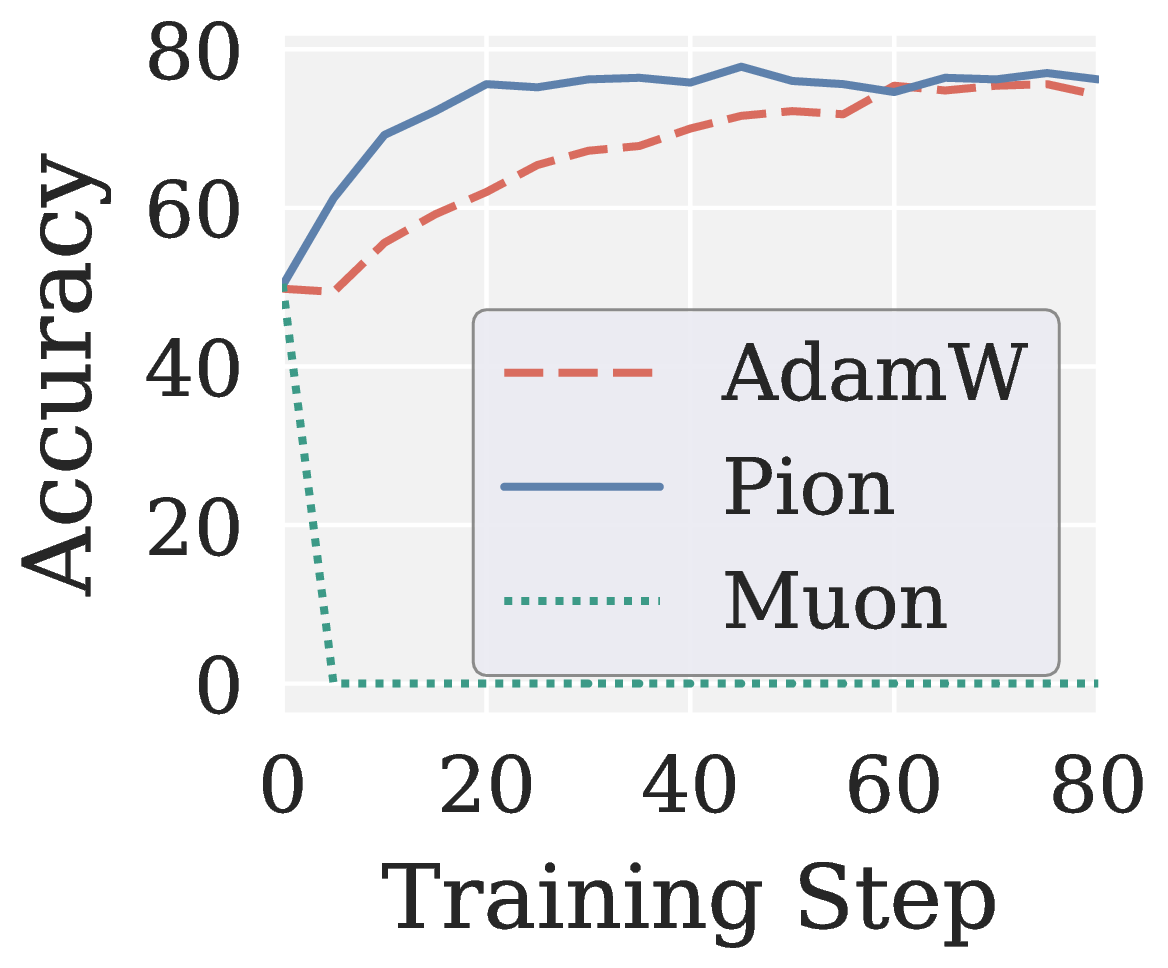
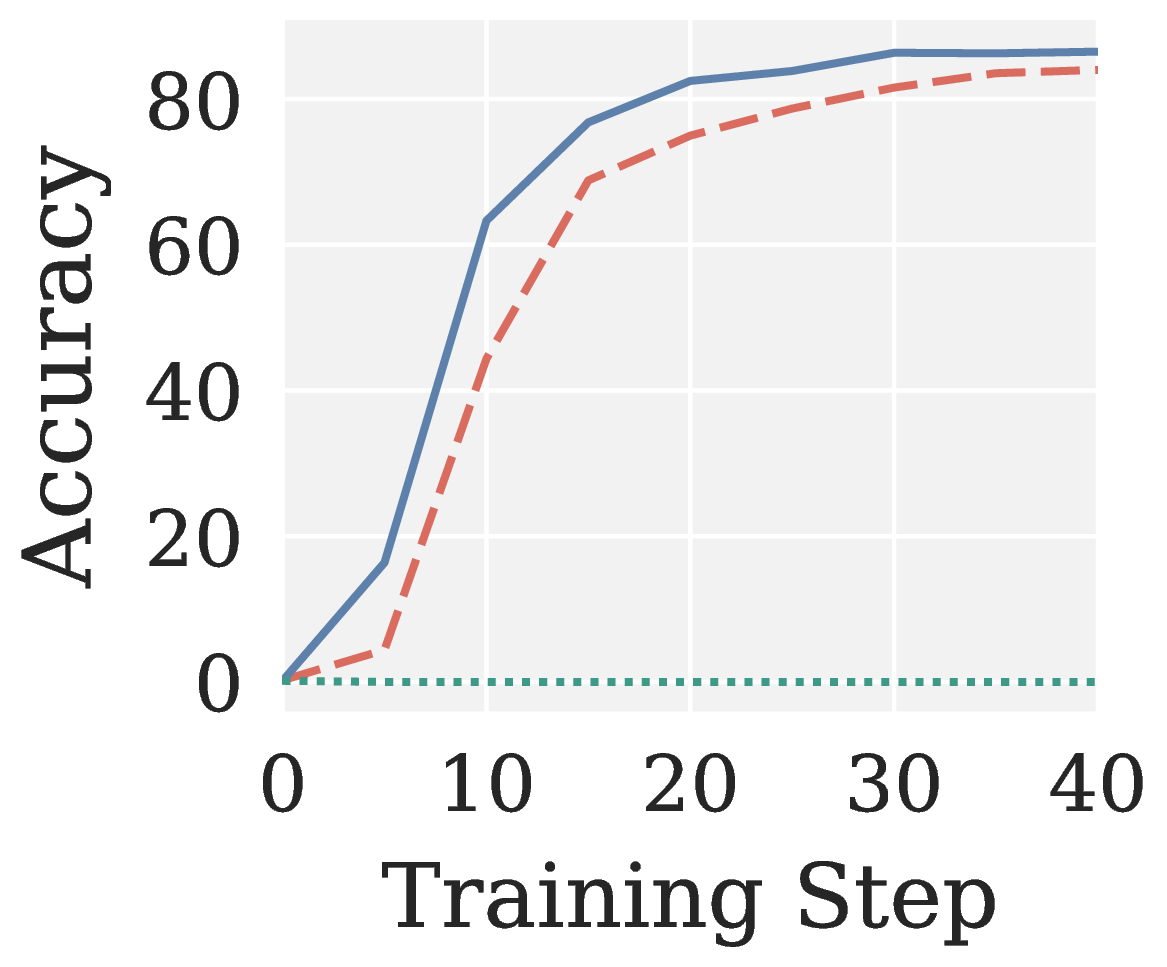
Figure 8. Validation accuracy versus training step on RLVR. Muon collapses; Pion outperforms AdamW.
Reverse Ablation: Direction of Spectral Shaping Matters
To verify that the gains come specifically from the high pass direction, we construct Low pass Muon (LPMuon), which mirrors Pion in NS structure and per step cost but flips the polynomial coefficients to induce a low pass mapping (contracts large singular values, amplifies small ones). LPMuon fails to train: its accuracy stays at the initial checkpoint.
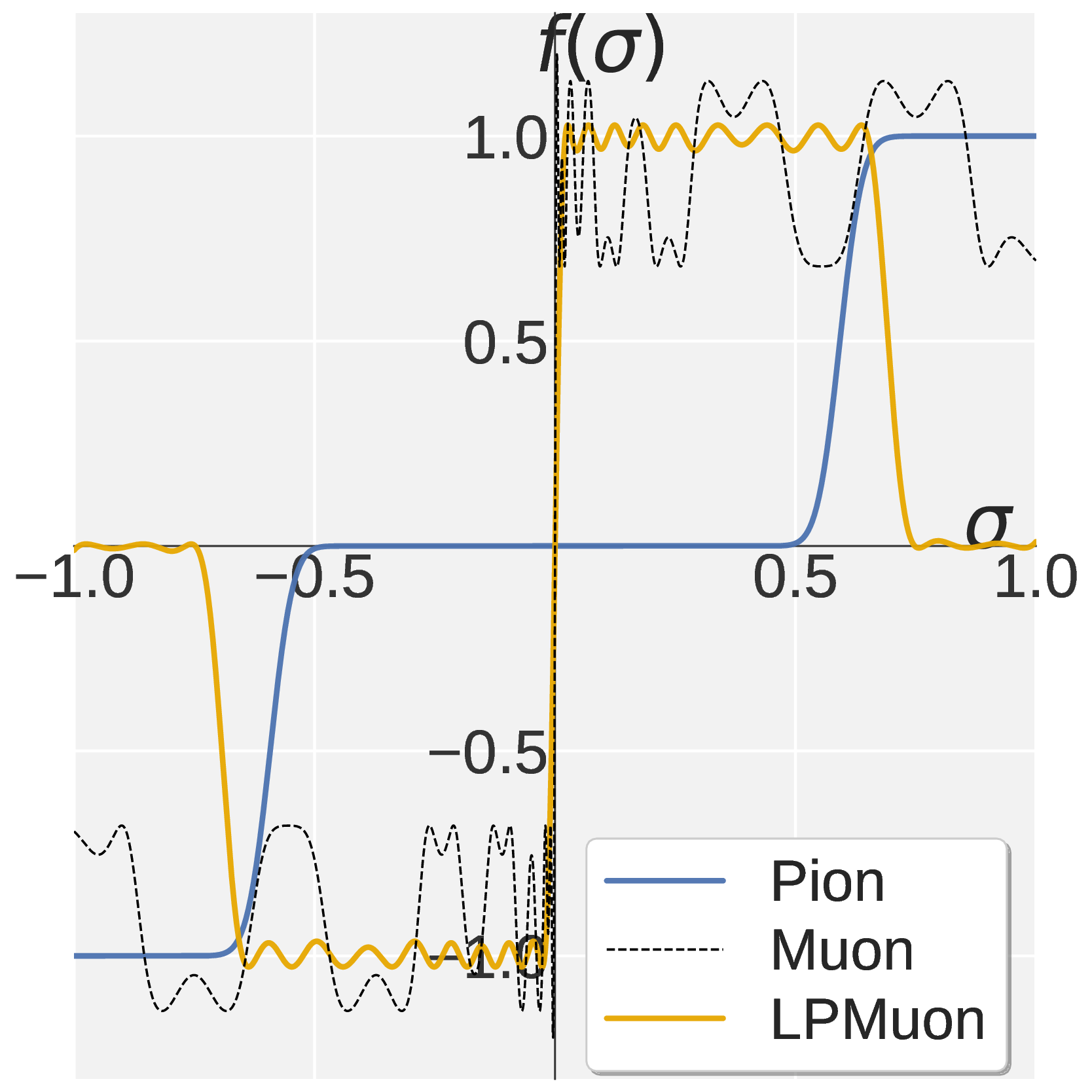
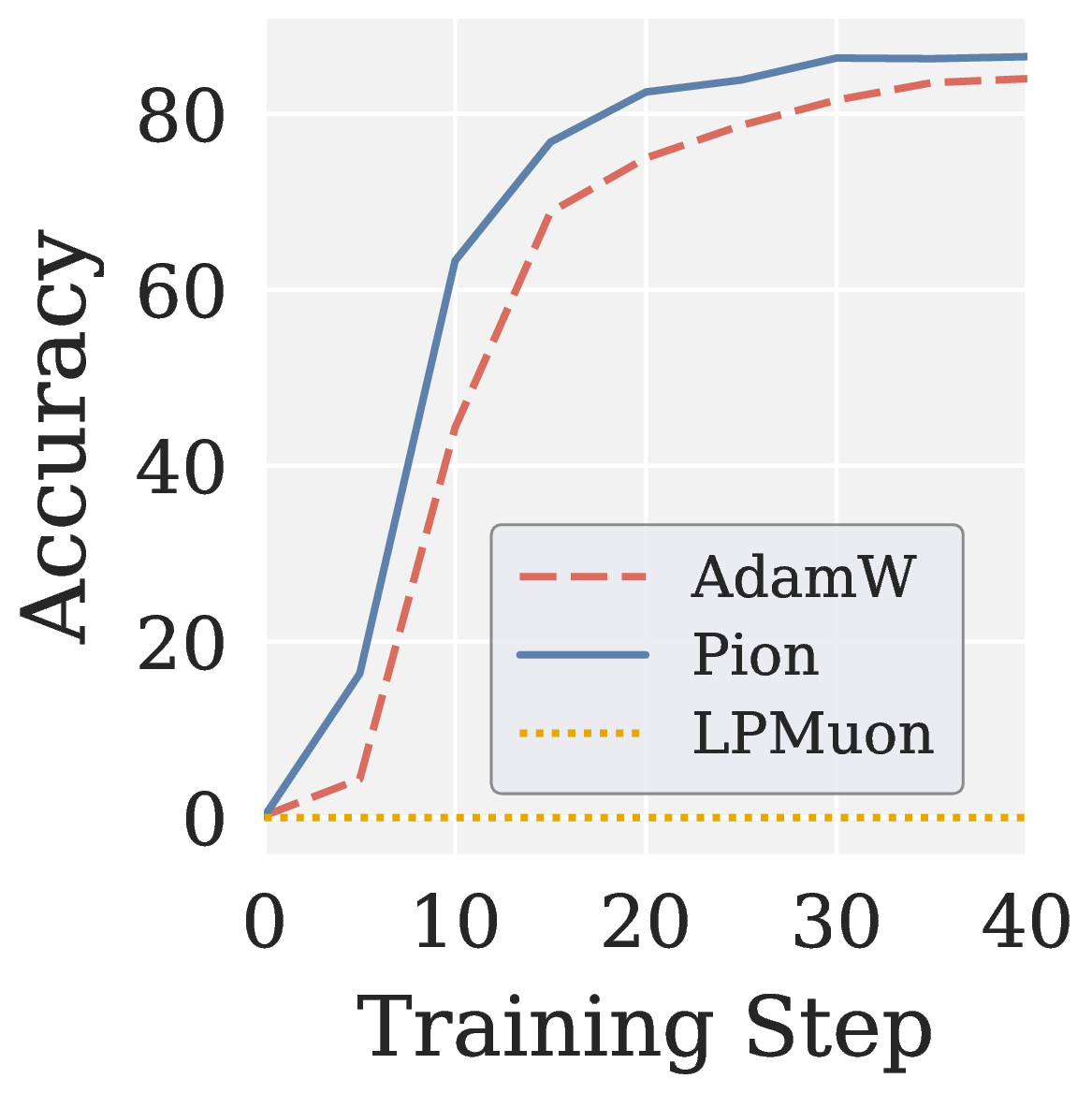
Figure 9. (a) Scalar map $$f(\sigma)$$ of LPMuon. (b) GSM8K accuracy of AdamW, Pion, and LPMuon (Qwen3 1.7B, GRPO). Combined with Muon's failure (no filtering) in Figure 8, this isolates the direction of spectral shaping as the key factor.
Conclusion
Muon’s uniform spectral whitening is a great inductive bias for LLM pretraining, where the input is text, the loss is classification, and the paradigm is supervised learning. Once we move along any of these three axes (vision and action modalities, regression and generative losses, or reinforcement learning paradigms), the gradient becomes either low rank or low SNR, and uniform whitening starts amplifying noise rather than informative signal.
Pion replaces uniform whitening with a spectral high pass, realized as a two stage Promotion plus Suppression NS iteration. The cost stays identical to Muon, the only knob is the step allocation between the two stages, and an optional per head reshape preserves the attention head heterogeneity inherited from pretraining. Across VLA training on LIBERO and LIBERO Plus and RLVR post training on Qwen3 1.7B and Qwen3 4B over MATH and GSM8K, Pion consistently beats AdamW and Muon, including settings where Muon collapses to zero.
We see this as evidence that matrix aware optimization beyond LLM pretraining benefits from spectral filtering rather than uniform whitening.
BibTeX
@article{fan2026pion,
title = {Pion: Rethinking Muon Beyond Pretraining via a Spectral High Pass Optimizer},
author = {Fan, Chongyu and Liu, Gaowen and Hong, Mingyi and Kompella, Ramana Rao and Liu, Sijia},
journal = {Preprint},
year = {2026}
}